Automated Ontology Discovery: How App Orchid Reduces Manual Data Modeling
February 1, 2026
Rehan Refai, VP of GTM
The Manual Data Modeling Trap
Most companies are stuck. They want to use GenAI for business intelligence, but they hit a wall: their data makes no sense to an LLM. Standard databases are full of cryptic column names like CUST_ID_01 or TXN_AMT_NET. Only the most technical users know what it means.
Even worse, companies have rarely codifed their language, so there’s no shared understanding of common terms. For example, “critical” means very different things in sales, service, and supply chain.
The common response is to build a semantic layer. If you’re following what experts are starting to recommend, it's to build an ontology. While traditional semantic layers focus on metrics and labels for reporting, ontologies model how business concepts relate to each other across systems, teams, and processes. They give AI a way to reason, not just query.
Building an ontology typically involves hiring expensive consultants to interview business users, map every table by hand, and write down definitions. This often takes months. By the time it’s done, the data has already changed.
What the Market Is Doing: From Semantic Layers to Ontologies
The industry relied on "semantic layers" to bridge the gap between messy data and BI. Snowflake and Databricks are now betting on that same approach to close the gap with AI through initiatives like OSI. But most companies find markup-language–based semantic layers brittle and hard to maintain, especially amid system changes, M&A, and evolving business processes.
Big players like Palantir and Microsoft are pushing the importance of ontologies. Palantir recently highlighted that 99% of problems solved on their platform are solved through the ontology.
But there is a catch. In systems like Foundry or Fabric, building these relationships is often still a manual, high-effort task. Users report that without strict governance, these ontologies quickly turn into swamps where specific, one-off objects clutter the system and break the logic.
App Orchid's Approach: Automated Ontology Discovery for AI-Ready Data
We don't believe in manual labor for machine-level tasks. App Orchid platform performs an Automated Ontology Discovery and Enrichment. Instead of starting with a blank slate, our system "reads" your database schema, analyzes the actual data, and suggests a candidate ontology. This is why the shift toward Automated Ontology Discovery is becoming a baseline requirement for any serious AI roadmap because it is the cheapest and most accurate to run.
The goal is to automate the "grunt work" that currently eats up 80% of their project timeline. Here's how that looks in practice:
Statistical Fingerprinting We use statistical discovery to find the "shape" of the data. By analyzing cardinality and distributions, the system can infer what a field actually represents. Why use a local guide versus using a satellite to map the terrain?
LLM-Enriched Metadata We’re using LLMs for what they do best: translation. The system uses LLMs to turn cryptic database headers into human-readable business descriptions. This creates a "Semantic Layer" that clarifies to an agent the business meaning of the underlying data.
Relationship Discovery Enterprise documentation is notoriously out of date. Automated discovery reads the underlying schema to find latent relationships. the "neural connections" between your CRM, your billing, and your operations. This builds a Graph that reflects how the business actually functions today, not how it was documented five years ago. In addition, since App Orchid can also measure the strength of the relationships between data, leading to new insight generation capabilities.
While other approaches spend weeks on blueprints and code, we focus on speed and precision, providing a working foundation in hours. automation isn't just faster to build — it's cheaper to run
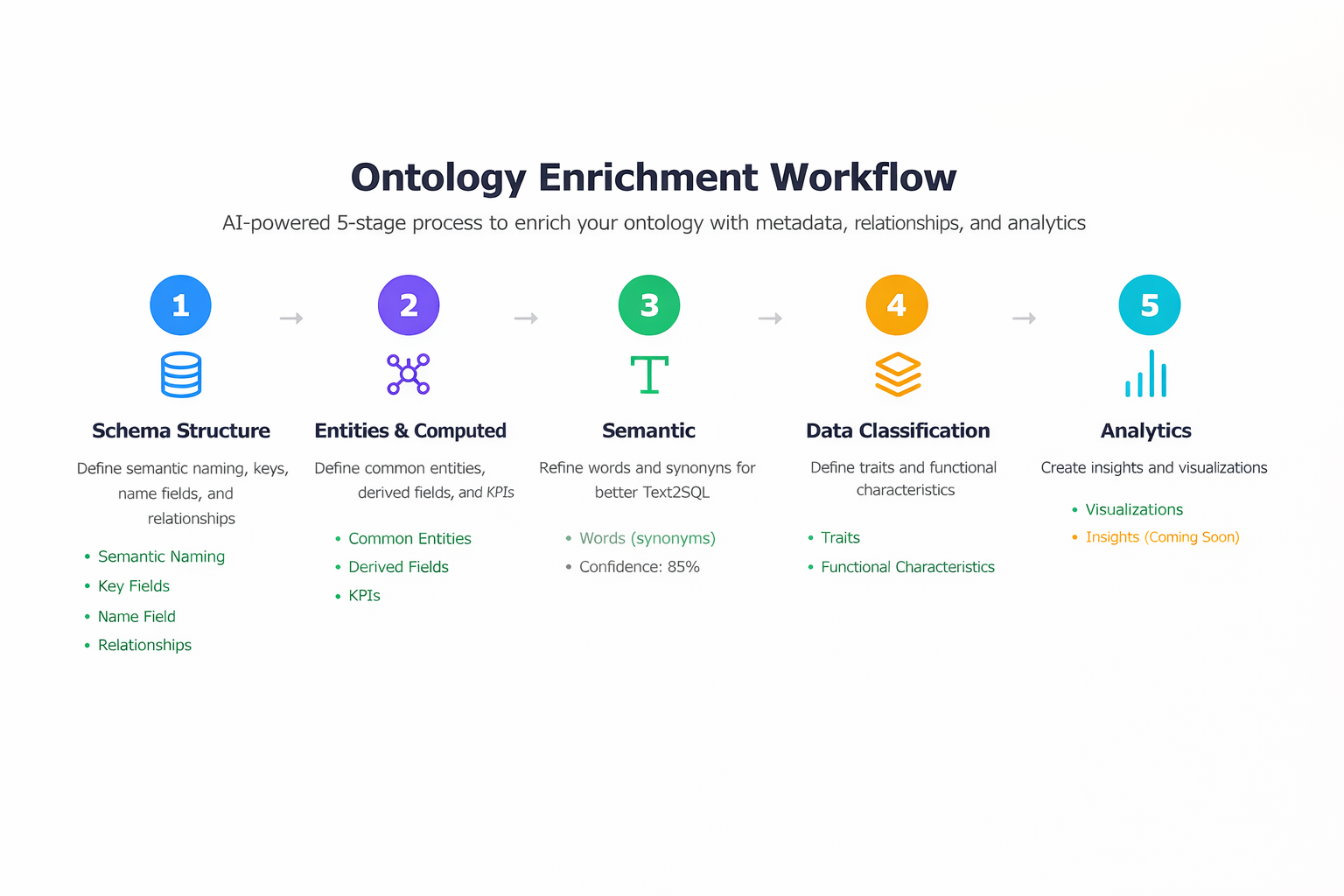
How Automated Ontology Discovery Works
Here is the workflow:
Data Source Selection and Schema Discovery: The process begins by selecting one or more supported data sources (databases, files, or federated sources). The platform retrieves metadata such as schemas, tables, and columns to understand the structure of the data. It also suggests calculations, metrics, and more.
Automatic Node Creation: Each selected table or data entity is converted into a Managed Semantic Object (MSO). Columns are mapped to MSO properties with inferred data types and default semantic roles (keys, names, measures, etc.).
Relationship Discovery: The discovery process analyzes primary keys, foreign keys, and structural patterns to automatically identify relationships between MSOs, forming the initial ontology graph. By reading the information schema, it determines how tables connect, forming the "connective tissue" of your data graph.
Statistics and Enrichment Generation: The platform generates statistics (such as distributions and cardinality) and applies default traits and linguistic metadata.
Words and Linguistics Discovery: It identifies low-cardinality values (like "Region" or "Status") that business users often mention in questions.
LLM Descriptions Generation: We use LLMs to look at the data structure to write human-readable descriptions of what each field actually means.
Trait Discovery: The engine automatically maps fields to a library of "traits" which add behavior to the underlying data. For example, temporal, or spatial traits tell the AI knows how to handle time-series or geographical data.
Analytics Suggestions: The tool automatically provides suggestion for KPIs, visualization and insights.
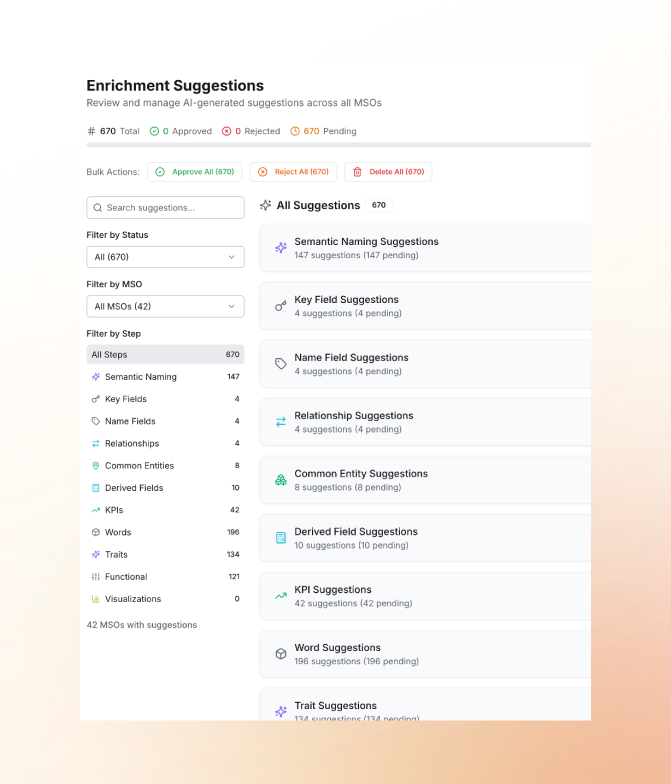
Discovery runs as background tasks, with progress and results visible through notifications. The resulting ontology can then be reviewed, validated, and refined by the human in the loop.
Human in the Loop Actions
Automation gets you 90% of the way there. The final 10% comes from your team's unique business knowledge. The platform presents a list of "Human in the Loop" tasks:
Confirm Traits: Ensure a date field is correctly identified as a "Fiscal Year" versus a "Calendar Year."
Validate Relationships: Confirm the joins between tables are business-accurate.
Review Synonyms: Add your company's "tribal language"—if "Revenue" is often called "The Top Line," you add that here.
Update Prompts: Fine-tune how the AI should describe specific entities.
Constant Improvement
The semantic ontology we are building isn't static. The system learns with usage. With every new question, every clarification and every new piece of data, the system enriches it.
If the LLM struggles with a specific term, a human clarifies it once in the ontology, and the AI never makes that mistake again. This iterative enrichment is how we achieve 99.8% accuracy on complex natural language queries such as the Spider 1 data set.
The Timeline
The shift from "data to insight" used to take a quarter. With App Orchid, it could take just a week or two. For example, for our Google Cortex for SAP build, we spent two total weeks to build an enriched ontology of a reference SAP system. the timeline looks like this:
Days 1-3: Connect your data sources. The system completes its initial scan and delivers a candidate ontology with recommendations.
Day 4-Week 2: Your team completes the human-in-the-loop validations and enrichment.
Week 3: You have a working, enriched ontology ready to power agentic AI and natural language analytics.
Stop building blueprints and start getting answers. Automated discovery is the only way to keep up with the speed of your business. This approach is superior for three reasons:
Compatibility & OSI: Our semantic layer is built for the modern ecosystem. We intend to provide full compatibility with Open Semantic Interchange (OSI). The Ontology JSON generated by our system can be seamlessly converted to OSI-compatible YAML. This allows you to bridge the gap between your existing semantic investments without a "rip and replace" of your infrastructure. It serves as a more agile way to maintain and version-control your semantic layer across multiple platforms.
AI Sovereignty: You own the business logic. By codifying your language into an ontology rather than burying it in LLM prompts, you maintain control over how your data is interpreted. You aren't locked into a single model's "opinion."
Operational Agility: Markets change and businesses pivot. When your business structure evolves, the automated discovery engine rapidly adapts the ontology to match. You don't wait months for consultants to remap your world; the system evolves as fast as your data does.
Time to value: Our approach is really, really fast.
App Orchid MCP Server: Our upcoming release of the Model Context Protocol (MCP) server changes the game for developer productivity. It allows LLMs and AI agents to "plug in" directly to your App Orchid ontology. Instead of manually feeding context to your agents, the MCP server provides a standardized, real-time interface. This means your AI tools instantly understand your business objects, relationships, and constraints without custom integration code.
The Bottom Line
Enterprise AI doesn’t fail because models aren’t smart enough. It fails because the data they’re asked to reason over has no shared meaning. Manual ontology building was a necessary step in the past, but it simply can’t keep pace with modern, fast-changing data environments.
Automated Ontology Discovery changes the equation. It turns semantics from a one-time project into a living system that evolves with your business. Instead of spending months defining what your data might mean, you start getting answers based on what it actually means today.
That’s the App Orchid way: less manual work, more shared understanding, and AI that finally operates with business context baked in—not bolted on later.
.png)
.png)



.png)