AI in Manufacturing: The Start Small, Prove Fast Playbook
In 2026, the AI conversation stops being theoretical.
For the last two years, enterprises have poured real money and real talent into a simple promise: “Talk to your data.” Whether the interface was a human analyst, a chatbot, or a shiny new agent, the goal was the same: ask a question, get the right answer, move faster and realize the promise of AI.
And yet, across the market, we’ve seen a sober reality set in: at enterprise scale, “talk to your data” has largely failed to deliver accurate, consistent, repeatable outcomes.
Not because the ambition was wrong. Because the foundation was.
This is why 2026 matters.
We are moving from an era of demos and promises to an era of decisions where AI must be trusted, governed, and operational, or it won’t be adopted.
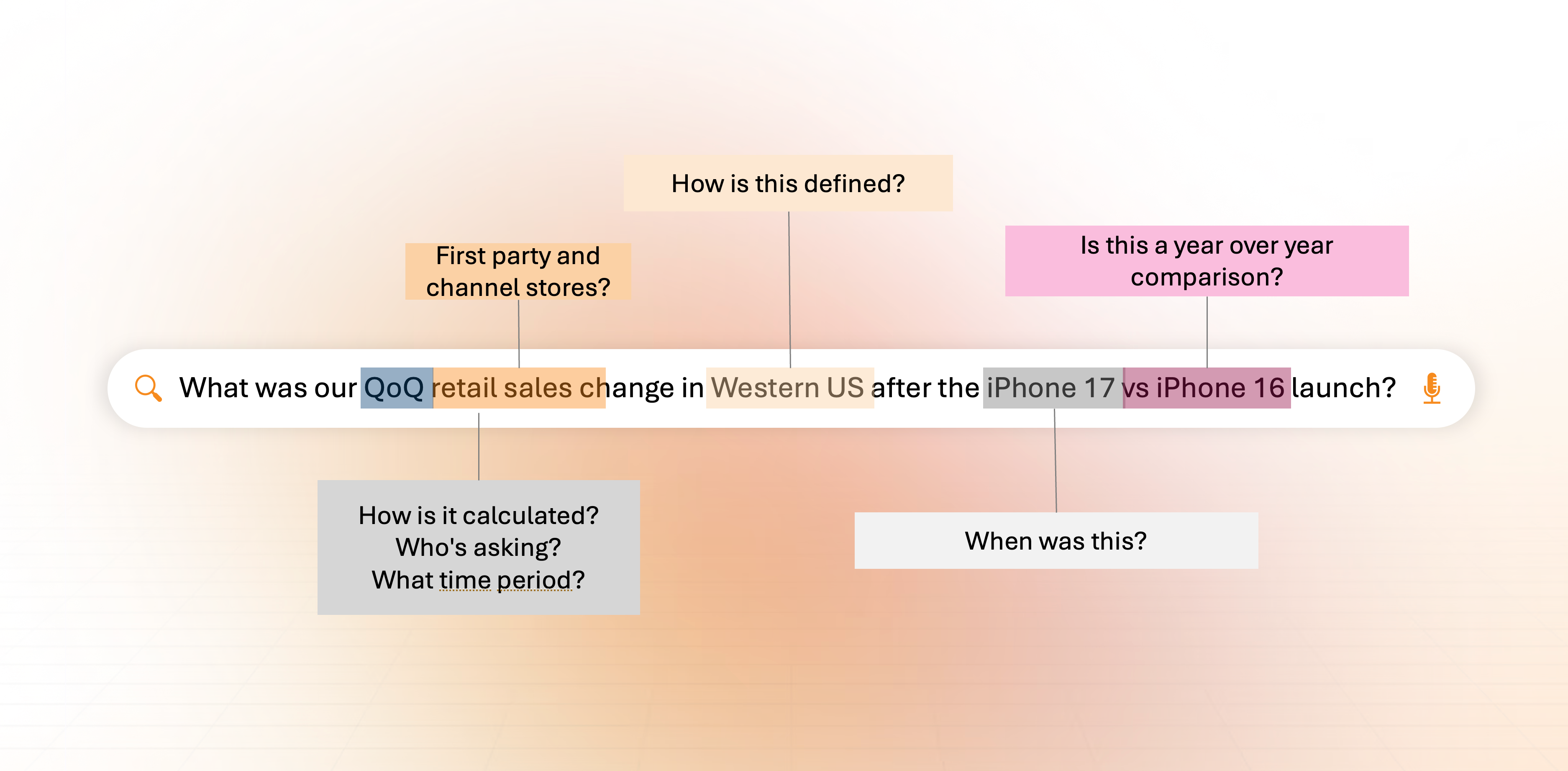
When large language models (LLMs) were exploded into the mainstream, many organizations assumed the missing piece was retrieval: connect an LLM to enterprise data using a vector database and RAG (retrieval-augmented generation), and you’d unlock conversational analytics across the business.
Over the last 18–24 months, countless teams have tried, and have spent heavily, only to hit the same wall:
The lesson is becoming widely understood: incremental improvements to retrieval won’t fix a structural problem.
You can make the horses faster. But eventually, you need a different vehicle.
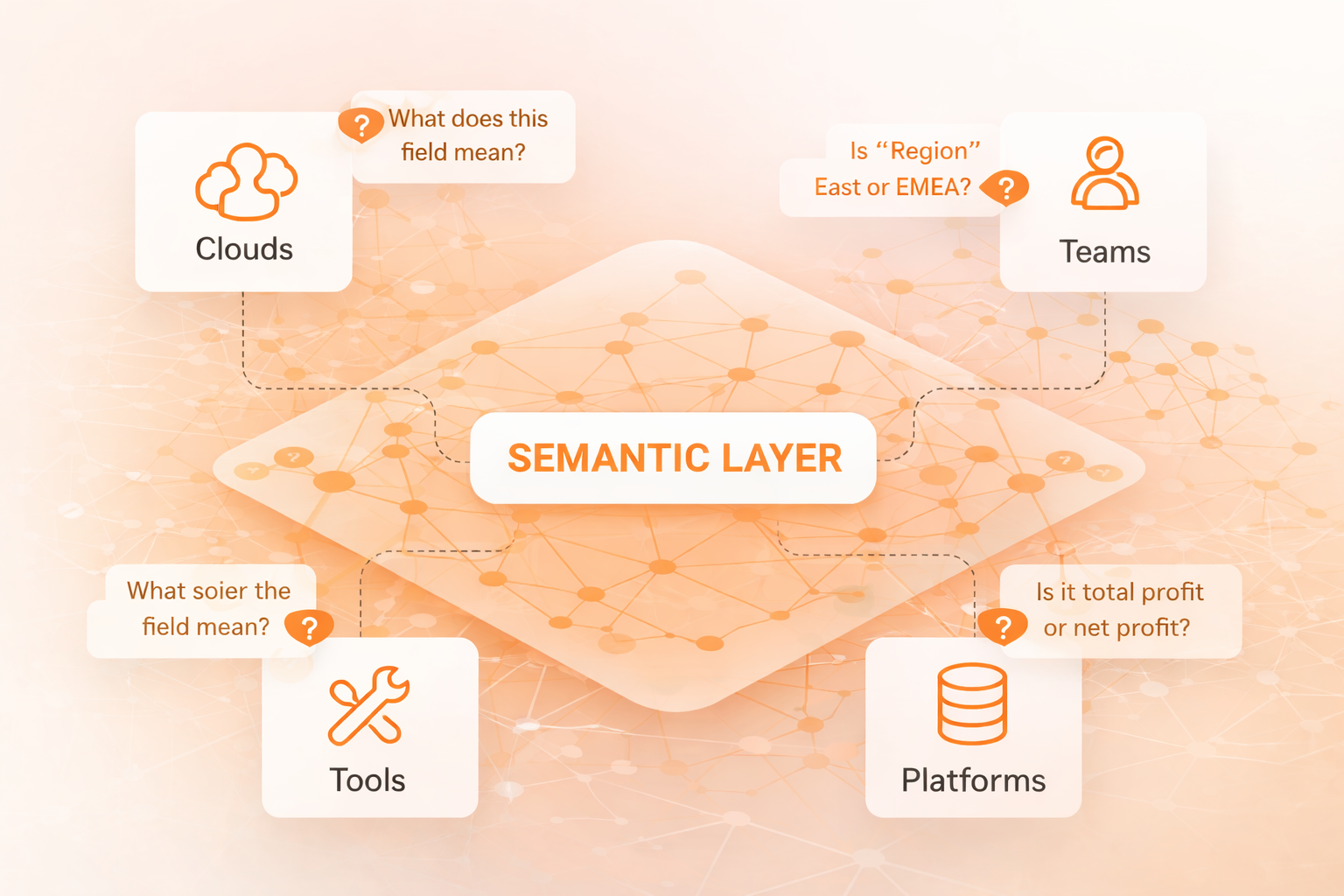
AI doesn’t fail in the enterprise because there isn’t enough data.
It fails because enterprises rarely have shared meaning across their data sources, including across teams, tools, clouds, and platforms. Humans compensate for this by asking follow-up questions, interpreting context, and knowing “what this field really means.” AI can’t reliably do that if the meaning isn’t clear.
That’s why one idea is quickly moving from “nice-to-have” to essential: AI cannot scale in the enterprise without a semantic layer.
In practical terms, that means an enterprise-grade way to represent what your data means beyond where it lives and how it’s formatted so that AI systems can reason over it, not hallucinate around it.
The clearest signal that 2026 will be a pivotal year is that this conversation has changed dramatically. Not long ago, much of the discussion was: What is a semantic layer, and why do we need it?
Now the discussion is: How fast can we get value and what approach will actually work across the business?
As more vendors rush into “semantic” territory, another market shift is accelerating and this is one that I believe will define AI strategy in 2026: Customers want to own their data AND the meaning of their data.
They are increasingly unwilling to let a point solution “own” the semantic definition of their enterprise, for good reasons:
In other words, it’s not enough to make AI work. Enterprises want it to work in a way that preserves sovereignty over their data, their definitions, and their future.
This is where independent architectures matter. When customers own the semantic layer, they can evolve it, govern it, and use it across tools without turning their business meaning into a walled garden.
At App Orchid, our core belief from day one was simple: meaning is the hard part.
The platform was built around creating an enterprise data ontology efficiently and capturing what data represents in business terms, not just technical metadata. We believed that shared meaning would become the limiting factor for analytics and, eventually, for AI.
That belief is no longer theoretical. It’s becoming the market consensus.
And because the world is now demanding outcomes well beyond the experimental phase, the differentiator is no longer who can demo a chatbot.
It’s who can deliver:
As we move through this year, the winners won’t be the organizations with the most pilots. They’ll be the ones that align around a few fundamentals:
2026 isn’t the year of “more AI.”
It’s the year the enterprise decides what it will tolerate and what it will no longer accept. And for the first time, the industry is converging on a simple truth: AI that actually works starts with data you can trust, meaning you can govern, and architectures you control.
That’s the future we’ve been ready for, and it’s here now.


Experience a future where data and employees interact seamlessly, with App Orchid.
.png)