.png)
Tokenomics: How App Orchid Minimizes Token Usage

Ontologies are having a moment. And here’s why: AI can’t function well without the right context.
Microsoft is another technology provider to put a spotlight on the issue with the announcement of Fabric IQ, a new semantic intelligence layer designed to give enterprises a shared, business-level understanding of their data. It’s an approach that mirrors what we’ve been building for years at App Orchid with our own Semantic Layer.
Discover what a semantic layer is and why AI needs it→
Microsoft isn’t alone.
Databricks, Tableau, and others are moving in the same direction. The momentum is clear: the industry is finally recognizing that high-quality context is the missing ingredient in enterprise AI, and ontology based semantic layers are the best way to deliver it.
In many organizations, the notion of a “semantic layer” has long meant a translation or presentation layer above the data warehouse or lakehouse, something that abstracts table names, field codes, and technical logic into business-friendly terms, metrics and relationships. In the era of AI, semantic layers take on a new role and are now an extremely valuable tool to ground LLMs in enterprise data for better answers and agentic behaviors.
We see two major approaches to these legacy semantic layers.
Many BI platforms (for example, PowerBI or Looker) include a semantic layer that is tightly coupled to that tool. The business metric definitions, join logic and hierarchies live inside the BI tool’s own model (or engine). That coupling creates some drawbacks:
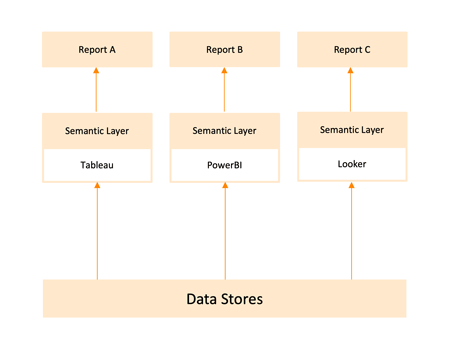
.png)
More modern semantic-layer initiatives still rely on declarative modelling (e.g., YAML or proprietary modelling languages) to define dimensions, measures, hierarchies and relationships. But this also creates practical challenges:
While the semantic-layer concept is sound, many implementations still struggle with consistency, re-use, governance, cross-tool interoperability and readiness for AI or conversational agents.
The good news is that the industry now fully recognizes these challenges and has introduced a partial solution: the Open Semantic Interchange.
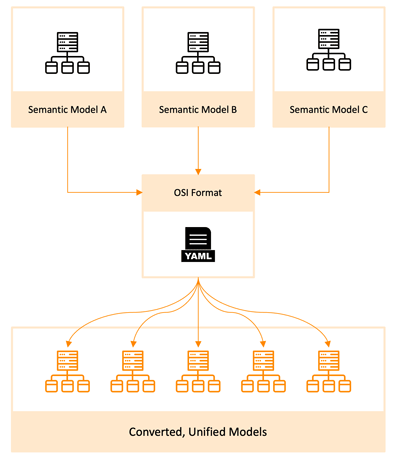
In 2025 we saw a major industry initiative: the Open Semantic Interchange (OSI). Partners such as Snowflake, Salesforce, dbt Labs, Alation and others are publicly committed to a vendor-neutral, open-source specification for semantic metadata.
Why is this significant? A few key motivations:
For decision-makers, OSI signals a turning point: semantic layers are moving from tool-specific abstractions to interoperable infrastructure for analytics and AI.
Many questions remain. How will older standards interoperate with newer approaches to storing semantics and context? How do these code first approaches adapt to changing definitions and context requirements based on role, use case or domain?
These announcements underline a pattern: semantic layers are evolving from “nice to have” abstractions in BI, to foundational blocks for AI, analytics, governance and enterprise data fabrics.
Major players are realizing that response accuracy depends on the degree to which data and semantics are grounded in an ontology, a structured model of business domain concepts, relationships, properties, and rules.
Why does this matter?
The Microsoft Fabric IQ announcement, for example, telegraphs teaching AI agents to understand business operations, not just fetch raw data. That capability only works if the semantics layer is highly enriched and structured as an ontology.
For the AI era, legacy semantic layers must evolve into semantic knowledge layers with ontologies that provide a legible, maintainable, and extendable structure.
App Orchid delivers a uniquely capable semantic layer for modern organizations. Here are some of the differentiators and development history:
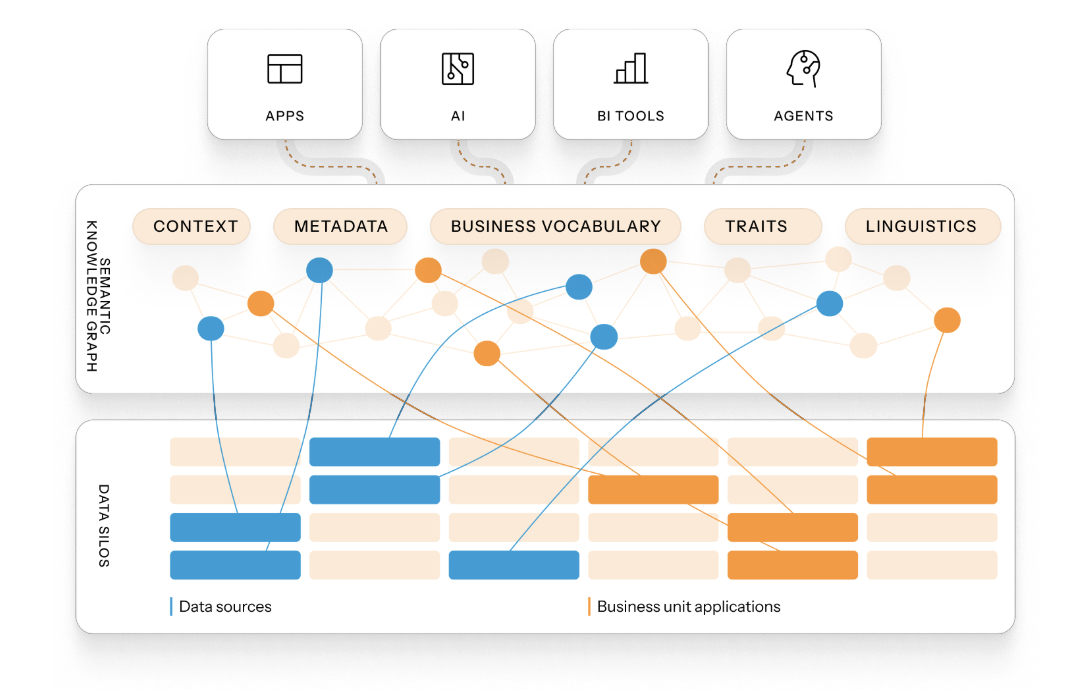
We launched our knowledge graph-based semantic layer eight years ago. It was initially focused on applications. With the introduction of ChatGPT, we launched Easy Answers, conversational analytics for enterprises that needed to query both structured data (warehouses, lakes) and unstructured data (text, documents, logs). Since then, we have refined our ontological approach, broken silos, and discovered millions of relationships to answer questions and validated in production environments how our semantic layer accelerates analytics, dashboards, and agent-based use-cases. Our references include enterprises in finance, hospitality, and industrial operations.
Our fundamental architecture differs from purely table/column or YAML semantic models. We discover a core ontology of business concepts (customers, products, contracts, renewals, events, channels, sentiment) plus relationships, vocabulary and domain context. This ontology maps downward into both structured data (tables, fields) and unstructured sources (documents, logs, chat transcripts). Because of this hybrid capability, our clients ask questions like: “Show me customer churn risk this quarter, including contract billing discrepancies and support ticket patterns.”
Such queries require semantics beyond simple column joins; they require domain reasoning and entity relationships.
We recognize the pain of manual semantic modelling. At App Orchid we embed semi-automated discovery: our system ingests metadata, schema, document taxonomies and uses entity extraction and relationship-mining to suggest ontology extensions, mappings and more. LLMs are leveraged to generate descriptions, meta data, and context. A human in the loop validates all suggestions. Typically, more than 90% of the ontology and context are auto-discovered in our engagements; the remaining manual modelling is domain-specific tuning and business-user refinement. That significantly reduces time-to-value.
Because our semantic layer is ontology-backed and governed, we deliver built-in auditing, versioning, and direct integration into conversational agents and analytics pipelines. Business users, data scientists, and AI agents all refer to the same definitions. That means one “churn” metric, one “renewal” definition, one “customer” concept, consistently computed whether in dashboard, notebook or agent query. That alignment is exactly what the market is demanding, especially with the rise of OSI and unified semantic standards.
Revise option: A new category of semantic layers is emerging as AI demands deeper meaning. For many years semantic layers lived within BI tools, with variable governance, limited reuse, and high manual effort. The rise of AI, conversational analytics, and agentic workflows has exposed the limitations of those architectures. Major vendors are racing to build semantic-layer capabilities (own models, catalog-driven semantics, unified metrics) and organizations are demanding “one version of the truth” across dashboards, notebooks, AI agents and apps.
OSI initiative solves part of the problem - semantics must be interoperable, governance-driven and usable beyond one tool. And as we’ve seen from Microsoft and Palantir, ontologies are the future that solves the other – dynamism and adaptability.
In this context, App Orchid offers a compelling alternative: an ontology-based semantic layer that spans structured and unstructured data, requires minimal manual modelling, supports governable reuse and is designed for AI and agent use-cases. For organizations looking to scale analytics, move into conversational and generative-AI workflows, and avoid semantic chaos, this approach is well aligned with the trajectory of the market.


Experience a future where data and employees interact seamlessly, with App Orchid.

.png)