
AI in Manufacturing: The Start Small, Prove Fast Playbook
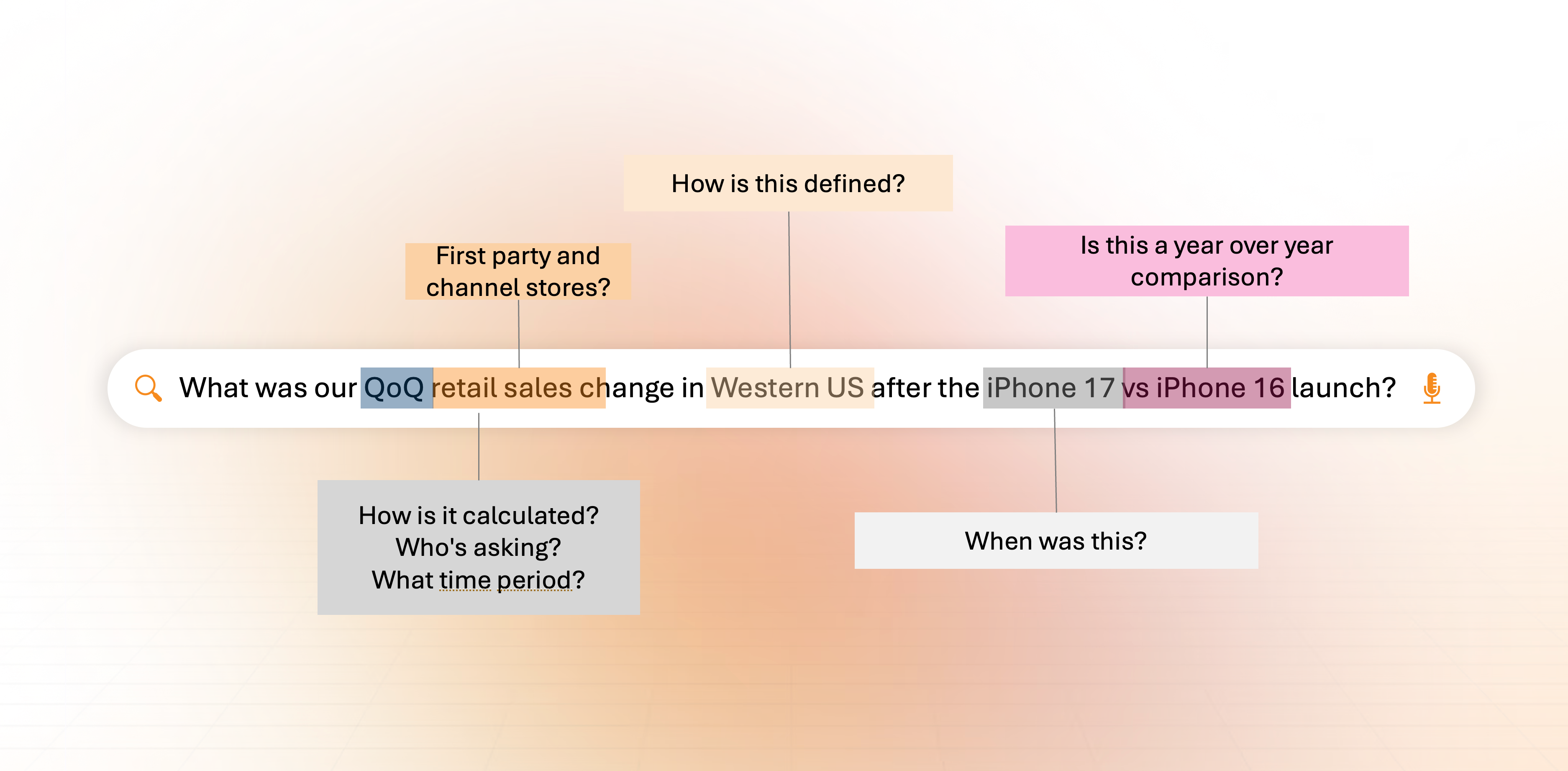
When a Director of Sales asks, "Compare our retail sales margin in Western US after the iPhone 17 launch vs the iPhone 16 launch?", a human employee can understand the context behind the question, parse tribal knowledge, find the data and organize it into an answer with ease.
But for questions like these, Large Language Models (LLMs) fall apart when the context behind that question is missing. Essentially, they operate context-blind, and that is one of the primary reasons so many AI initiatives never make it to production. LLMs need to:
Current approaches (Copilots, LLM+MCP of your Data Warehouse, etc.) unveil a software stack problem. The perceived simplicity of the question masks a massive coordination failure across fragmented enterprise architectures that lack universal enterprise context.
A "simple" question like the one above is actually a request for a multi-step analytical reasoning chain. Text-to-SQL assumes that a database schema is a perfect map of reality. It isn't. An LLM tasked with this calculation will fail due to:
To bridge the gap, organizations are quickly coming to terms with the fact that a Universal Enterprise Context Layer is required to address the friction points:
In an enterprise architecture, the Context Layer acts as the bridge between raw data and AI agents. It captures the institutional knowledge, business rules, relationships, and definitions that help contextualize data for AI, whether that is regional sales hierarchies, product launch calendars, customer classifications, operational processes, or regulatory requirements.
Just as humans rely on context to make informed decisions, AI agents rely on context to act predictably. The difference between a good decision and a bad one is rarely access to more data. It is having the right context. Context helps us understand what information matters, how it relates to other information, and what action should be taken next.
Without context, an AI agent sees data points. With context, it understands how those data points fit together within the reality of the business.
App Orchid enables this through Context Engineering, a disciplined approach to transforming enterprise data from machine-readable to machine-understandable. By organizing fragmented data, metadata, business rules, and relationships into a governed semantic layer, App Orchid creates a shared understanding of the enterprise that AI agents can reason against. Think of it as a universal semantic layer — a governed, ontology-driven model of the enterprise that makes data AI-ready before it ever reaches an agent.
The result is more accurate answers, more consistent decisions, and AI outputs that remain aligned with corporate truth. App Orchid's approach achieves 99.8% accuracy on the Spider benchmark.
The primary "curse" of an LLM is its inherent flexibility, a quality that drives conversational fluency but can undermine analytical precision. To be effective, the probabilistic LLM must be constrained to act as a controller for deterministic actions, using the Context Layer as the immutable source.
AI agents need guardrails to ensure responses are grounded in trusted enterprise knowledge. The Context Layer provides that foundation, serving as the authoritative source for definitions, relationships, business logic, and corporate truth.
App Orchid extends this foundation through LLM Interpretation Modes that balance flexibility with control based on the task at hand:
The goal is not to restrict AI. The goal is to ensure AI operates with the same context, understanding, and decision-making framework that trusted employees use every day.
Organizations that invest in building a governed context layer create the foundation for AI that is accurate, trustworthy, and aligned with how the business actually operates. Because in the end, success with AI is not about giving models access to more information. It is about giving them the context needed to turn information into understanding, understanding into decisions, and decisions into action.
Does your current context strategy address the six layers of architectural friction required for AI to answer a business question accurately? Let's talk.


Experience a future where data and employees interact seamlessly, with App Orchid.
.png)
