
AI in Manufacturing: The Start Small, Prove Fast Playbook

One of the most fascinating—and often overlooked—insights from cognitive science is that understanding cause and effect is not fully developed early in life. Research in developmental psychology, particularly building on Piaget & Inhelder (1972), shows that amore mature understanding of causal reasoning only consolidates during the formal operational stage, typically around ages 11–12 and beyond. Even then, this ability continues to refine throughout adolescence and into adulthood.
More recent work in cognitive science (e.g., Gopnik et al., 2004; Pearl, 2009) further reinforces that causal reasoning is actively learned and refined, rather than emerging automatically from observational data alone.
If it takes over a decade for humans to begin reasoning properly about cause and effect, what should we expect from AI systems trained primarily on pattern recognition?
Cursor, Claude Code, Codex—we are witnessing a remarkable moment in technology. Standard coding is rapidly becoming a solved problem. But here is the uncomfortable truth: Data Science is not coding.
In this context, many companies claim to offer systems capable of, within minutes, building machine-learning models, visualizing data, extracting “core insights,” and producing complete executive reports—often including generated Python code.
However, the creation of advanced models alone does not define Data Science. Rather, Data Science rests on a fundamental triad:

There is little doubt that modern AI agents can address the third component. Recent industry research highlights the gap clearly: a leading frontier coding agent scored just 32% on a data benchmark due to a lack of enterprise context. By incorporating specialized skills, deeper contextual awareness, and memory for data pipelines, performance improved to 71%. This represents a meaningful advancement, particularly for pipeline engineering.
However, enterprise context for pipelines and enterprise context for analytical reasoning are fundamentally different. Knowing how to connect to a data source, handle schema changes, or monitor a pipeline is not equivalent to understanding that employee gym usage does not cause job satisfaction—even when the two variables exhibit strong correlation in the data.
This is where App Orchid positions itself within the data analysis landscape. By relying on ontology-driven, semantically structured databases and leveraging probabilistic programming, we aim to bridge two traditionally distinct dimensions: enterprise context and analytical reasoning. In doing so, we combine the operational understanding of complex data ecosystems with the principled rigor required for sound statistical and causal inference.
Consider the following question: “I want to wash my car, but the car wash is only 50 feet away. Should I walk or drive?”
Many large language models will confidently answer: “You should walk—it is very close.”
At first glance, this sounds reasonable. But it completely misses a key causal constraint: You cannot wash your car unless the car is physically at the carwash. Unless you plan to carry your car on your back, walking is not a valid solution. This is not a failure of intelligence in the traditional sense—it is a failure of causal reasoning.
This brings us to the current wave of AI agents. Automating the plumbing of data science—data ingestion, cleaning, feature engineering, and model fitting—is a remarkable productivity leap. But let us be clear: if a system lacks one of the most fundamental skills of a data scientist—critical thinking and causal reasoning—then speed becomes a liability, not an advantage.
A model that cannot reason about cause and effect can still produce polished code, elegant visualizations, and confident conclusions. Yet those conclusions may be completely wrong. Not slightly off. Not noisy. Fundamentally wrong.
The real risk is not that AI fails, but that it appears to succeed while silently violating the logic of the problem. And when that happens, we are not automating intelligence—we are automating wrong at scale.
Consider a simple exercise: ask an AI system to predict the violent crime rate per 100,000 residents in the United States using per capita consumption of regular ice cream frozen products in the United States. Standard agents are typically able to construct a complete pipeline quickly, producing visually appealing plots and even achieving predictive accuracy of 70% or higher.
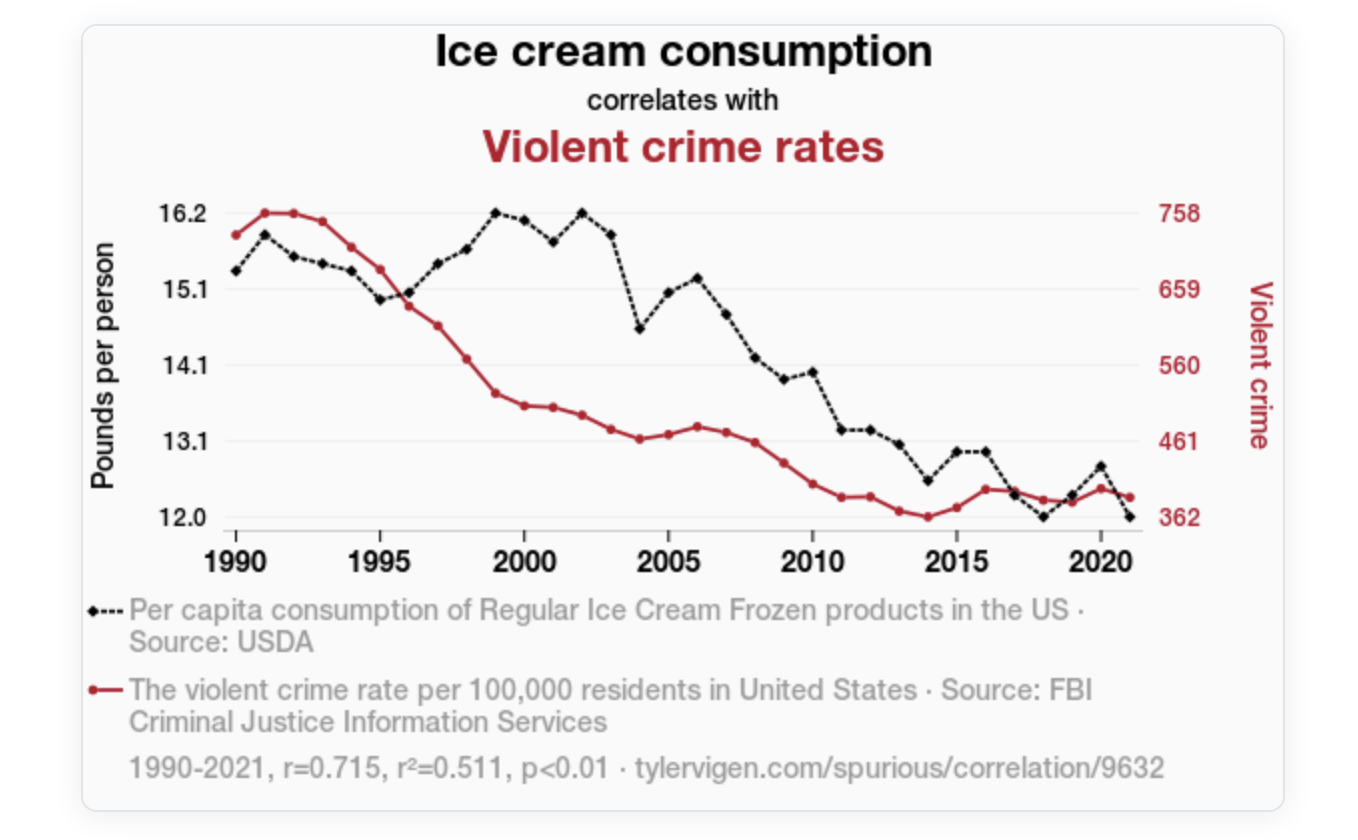
If this were not enough, such agents may even attempt to “explain” the relationship: “As ice cream consumption decreased, brain freeze incidents also decreased, resulting in fewer people experiencing sudden bursts of intense pain in their heads that could trigger violent outbursts.”
This is not intelligence. This is pattern recognition without reasoning.
As every Statistics 101 student learns: Correlation does not imply causation. Yet most automated systems today violate this principle at scale.
The danger is not that AI fails. The danger is that it looks correct while being fundamentally wrong.
A policymaker trusting such systems could conclude: Let’s increase ice cream consumption to reduce crime. That is not just incorrect. That is dangerous decision-making powered by artificial confidence.
In the ice cream example, the correct conclusion is that violent crime rates cannot be predicted based on ice cream consumption. Even more concerning, a policymaker relying solely on agents that ignore semantic and ontological structure might propose increasing ice cream consumption as a strategy to reduce crime—which, while perhaps not a bad idea given that most enjoy ice cream, would be entirely unjustified from a causal perspective.
At App Orchid, we take a fundamentally different approach. We believe that: A true AI Data Scientist must reason, not just compute.
App Orchid addresses this gap by rethinking the foundation of automated data science. By combining ontology-driven data representations with probabilistic programming, we integrate expert knowledge directly into the modeling process.To achieve this, we combine three key elements:

This allows our systems to:
In the ice cream example, our models do something simple—but powerful: There is nothing to learn here.
And that is the correct answer. In other words, the model correctly identifies that there is no predictive or causal relationship—returning zero meaningful predictive power, in contrast to the misleading results often produced by the so-called “incredible data scientists.”

The future of Data Science is not about faster pipelines. It is not about prettier dashboards. It is not about generating more code. It is about building systems that understand the problem before solving it. Most agents today deliver speed. App Orchid delivers understanding.
The emergence of automated data science agents represents a significant step forward in productivity. However, as illustrated throughout this discussion, automation without understanding is not intelligence. A truly incredible Data Scientist—human or AI—must unify:
Most systems today cover two out of three. They can generate code, fit complex models, and deploy scalable pipelines with impressive speed and efficiency. Yet, they consistently fall short in the most critical component: understanding the problem within its real world, semantic, and causal context.
App Orchid enables a new class of systems that unify all three pillars of Data Science. Not just faster pipelines. Not just better models. But agents that understand what they are modeling, why it matters, and how to reason about it correctly.
This is the difference between automation and intelligence. This is what defines a truly Incredible Data Scientist.
Because in the end: Intelligence is not about predicting patterns. It is about understanding reality, and use it to make informed decisions.
1. Piaget, J. & Inhelder, B. (1972). The Psychology of the Child. Basic Books, New York.
2. Gopnik, A., Meltzoff, A. N., & Kuhl, P. K. (2004). The Scientist in the Crib: What Early Learning Tells Us About the Mind. Harper Collins.
3. Pearl, J. (2009). Causality: Models, Reasoning, and Inference (2nd ed.). Cambridge University Press.
4. Spirtes, P., Glymour, C., & Scheines, R. (2000). Causation, Prediction, and Search (2nd ed.). MIT Press.
5. Albuquerque, P. et al. (2026). SPINE: Semantic-Aware Prior Elicitations with Inference via Embeddings for Bayesian Causal Discovery. .
6. Ice cream consumption correlates with violent crime rates. tylervigen.com/spurious/correlation/9632.1990–2021, r = 0.715, r² = 0.511, p < 0.01.


Experience a future where data and employees interact seamlessly, with App Orchid.
.png)
